Avantis Backend Tech Stack 🚀

สวัสดีครับนักอ่านทุกท่าน วันนี้ทีมพวกเรา Avantis มีความตั้งใจในการจะมาแชร์ Tech Stack และประสบการณ์ใช้งานต่างๆ รวมถึง Benefit กับ Tradeoff ของ Stack นั้นๆ อีกด้วย
แล้วพวกเราคือใคร พวกเราเป็นคนที่หลงรักในการเรียนรู้ พัฒนาตัวเอง 👨💻 พวกเรายังชอบ Expore 🔥 สิ่งใหม่ๆ อยู่เสมอ พวกเราไม่กลัวว่า Learning curve สูงแค่ไหน พวกเราก็ไม่กลัวพร้อมจะ Take Time และ Learning ไปด้วยกัน ❤️
Table of Contents 📑
· Programming Languages
· Infrastructure
· Infrastructure as Code(IaC)
· Data Pipeline
· GitOps
· Application Development
· Data Store
· Logging & Monitoring
· Testing
· On chain
· Other
· Future
· ConclusionOverall Context
- We are professionals. We are not scared of a learning curve.
- High performance.
- High maintainability.
- High scalability.
- High reliability.
- Automate Everything. We hate manual tasks.
Programming Languages 📜

Domain-Specific Context
- Compile Time Language: We prefer to have an error at compile-time instead of at a runtime one.
- Static Strong Typing with Modern Type Inference.
- Functional Programming Paradigm.
Rust
Benefit
- (Very) High performance.
- High maintainability.
- Compile Time Lang, with a very smart compiler, emphasizes memory safety.
- Static Strong Typing with Modern Type Inference.
- Rust encourages engineers to write good code.
Tradeoff
- ใช้พลังในการเรียนรู้สูงพอสมควร ถ้าไม่เคยเขียนโปรแกรมมาก่อน ไม่แนะนำให้เริ่มเป็นภาษาแรกเพราะมันเข้าใจยาก!
- Some libraries are not fully developed.
Backend ทั้งหมดเราใช้ Rust เป็นหลัก เราใช้ Rust เพราะเรื่องความเร็วที่ใกล้เคียงภาษา C/C++ เรื่องการจัดการ Memory Safety และตัว Compiler ที่โคตรฉลาดทำให้พวกเราหลงรักในตัวภาษา
ทีมเราคุยกันแล้วว่า เรารับกับ Learning Curve ในช่วงแรกของมันได้ และเราอยากได้คนที่ Geek พอๆ กับเรา มาสนุก มาเรียน Rust ไปด้วยกัน เข้ามาร่วมทีม แถมด้วยความที่เราจะไป On-chain ตัว Rust ก็เป็นภาษา hothit ตัวหนึ่งนอกจาก Solidity สำหรับโลก Blockchain ทุกอย่างก็เลยเหมาะเจาะพอดี เราจึงใช้ Rust เป็น Default language ของฝั่ง Backend ปัจจุบันตัวภาษาก็เป็นที่รักใคร่ของนักพัฒนาใน Stackoverflow Developer Survery 3 ปีซ้อนเลยทีเดียว
Kotlin
Benefit
- High performance, but can’t compete to rust.
- High maintainability.
- Compile Time Lang.
- Static Strong Typing with Modern Type Inference.
- มี libraries ให้ใช้อย่างแพร่หลาย
Tradeoff
- Moderate Learning Curve.
เนื่องจากเรามี Service ที่ทำงานร่วมกับทางทีม frontend เรียกว่า BFF(backend for frontend) แล้วทางทีม frontend เลือกใช้ Kotlin เพื่อไม่ให้ทาง frontend ปรับตัวจนมากเกินไป
Typescript
Benefit
- Low Learning Curve. Most dev nowadays can code in Typescript.
- Static Strong Typing.
- มี libraries ให้ใช้อย่างแพร่หลาย
Tradeoff
- Moderate performance.
- Type Inference is inferior compared to our other choices.
ที่เลือกใช้เพราะตัว Pulumi Support Typescript เป็นหลัก สำหรับตัวอย่าง Code เวลาจะขึ้น Infra ของ Pulumi นั้นหาได้ง่าย และปัจจุบันยังไม่ Support ภาษา Rust ไม่งั้นพวกเราก็คงใช้ภาษา Rust แทน 😊
Infrastructure 📡

Domain-Specific Context
- Cloud Infrastructure.
- High scalability.

Networks
VPC ถูกแบ่งออกเป็น 3 VPC คือ
- dev-vpc — ใช้วาง Infrastructure ที่ใช้บน Development environment ทั้งหมด
- prod-vpc — ใช้วาง Infrastructure ที่ใช้บน Production environment ทั้งหมด
- xpressfeed-vpc — ใช้วาง Infrastructure สำหรับติดตั้ง xpressfeed software จาก S&P และเป็น vpc กลางที่ทำ vpc peering เชื่อมไปยัง dev-vpc และ prod-vpc
EKS Clusters
Infrastructure ทั้งหมดของ Avantis จะถูก deploy บน AWS ที่ Region Singapore โดย service กว่า 80% จะถูกวางไว้บน Multi-AZ EKS Clusters เพื่อให้ service มี High Availability บน 3 Availability Zone โดยเราแยก EKS ออกเป็น 3 cluster คือ
- Service Cluster — ใช้ในการ Deploy Core Service ของ Avantis ทั้งหมด
- Workflow Cluster — ใช้ในการ Run ETL Workflow ข้อมูลเข้ามาโดยจะใช้ Argo Workflows เป็นหลัก
- Local Cluster — ใช้ Run Monitoring Service ต่างๆ เพื่อตรวจสอบว่าระบบทุกอย่างทำงานได้อย่างปกติ
ทุก Cluster จะถูกวางไว้ใน Private Subnet โดยที่
- Outbound traffic ของ Service บน Cluster สามารถออก Internet ได้ผ่านทาง NAT gateway
- Inbound traffic จาก Internet ต้องวิ่งผ่าน Route53 → API Gateway → VPC Link → Network Load Balance → Ingress-Nginx หรือผ่านการ connect จาก OpenVPN เท่านั้น
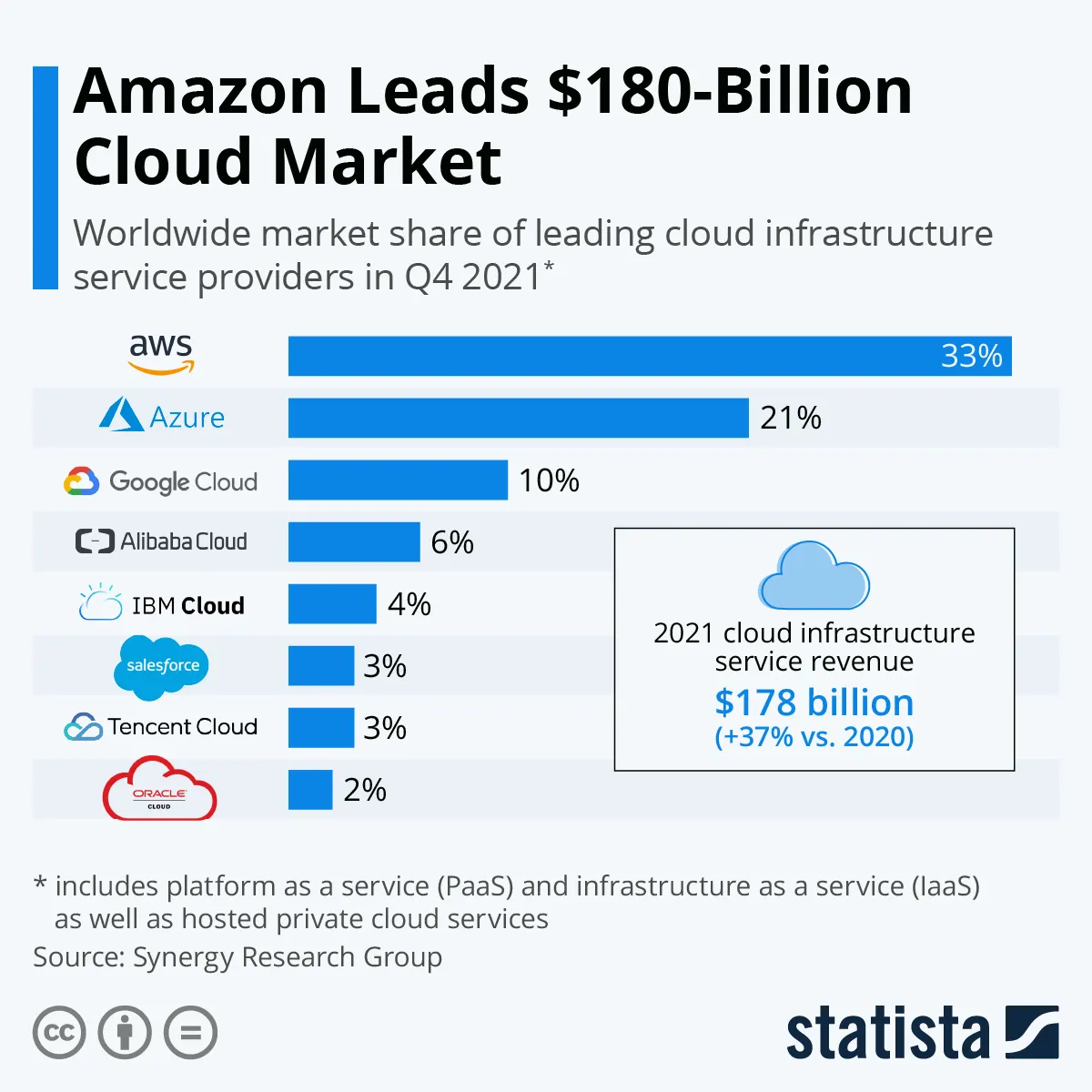
Amazon Web Services
Benefit
- ปรับแต่งได้มากสุดเมื่อเทียบกับ Google Cloud, Microsoft Azure, Digitalocean
- ราคาถูก
- มี service ให้ใช้หลากหลาย
- Support region หลากหลาย
Tradeoff
- Learning curve สูง
- อาจจะมีค่าใช้จ่ายการเรียน เนื่องจากต้องจ่ายค่า Cloud จริงๆ
ปัจจุบันก็มีบริษัทใหญ่ๆระดับโลกเลือกใช้ AWS เช่น Netflix, Twitch, Twitter, LinkedIn, Facebook, Epic Games, Disney, NASA
Kubernetes
Benefit
- High scalability.
- High maintainability.
- High reliability.
Tradeoff
- Learning curve สูง
เราเลือกใช้ EKS เป็น manage service ของ AWS สร้างทุกอย่างโดยใช้ Pulumi โดยพวก node group ใน k8s เราใช้เป็น manage node ทั้งเป็นแบบ Spot กับ On-demand ผสมกันตามความเหมาะสมของ Service ที่ใช้งานนั้นๆ เพื่อ Optimized cost
ตัว Deployments ต่างๆ ของเราจะ Set Limit Resource เพื่อช่วยในเรื่อง QoS (Quality of Service) ไม่ว่าจะเป็น req/sec ของตัว Service, การ Scaling ที่เราสามารถคำนวณได้ว่าต้องใช้เครื่อง Size ไหน แล้วกี่เครื่องบ้าง และยังช่วยเรื่องไม่ให้ตัว pod แยก Resource ระหว่าง deployment ด้วย
ตัว Scaling ตอนนี้หลักๆ เราใช้ HPA ดูตามการใช้งาน CPU และ Memory ของ Sevice นั้นๆ และมีอีกตัวที่เราจะเลือกใช้คือ KEDA เป็น Event-driven Autoscaling สามารถ Scaling ผ่าน Metics ต่างๆ ได้เช่นจาก AWS CloudWatch, Prometheus, Kafka, etc.
Linkerd
Benefit
- Ultra-lightweight, ultra-simple, ultra-powerful. security, observability, High performance and reliability.
- The only graduated CNCF-hosted and 100% open-source service mesh.
- Fast Integration.
- Latency น้อยกว่า Istio
- Setup ง่าย
Tradeoff
- Feature น้อยกว่า Istio (เช่น Rate Limiting, Circuit Breaking, Dark Release)
- Community น้อยกว่า lstio
- Abstraction layer network.

ทำไมต้องเราต้องใช้ Service Mesh?
เริ่มต้นด้วยการเปลี่ยนจาก Monolith มาเป็น Microservices นั่นหมายความว่า จะเกิด Service จำนวนมากที่แยกตัวกันออกมา ส่งผลให้การพัฒนาระบบยืดหยุ่นขึ้น (แต่ในบาง Serviceใช้แบบ monolith ก็อาจดีกว่า ต้อง Tradeoff เอา) และส่งผลให้ระบบ Scale ง่ายขึ้น แต่การดูแล การจัดการ ของภาพรวมทั้ง Infrastructure นั้นไม่ง่ายเลย!!
ประโยชน์ของการใช้ Service Mesh:
- การ connect ระหว่าง service ด้วย proxy sidecar ที่จะจัดการเรื่อง mTLS, routing, security, etc ให้เราอัตโนมัติ
- Tracing การทำงานของ service
- การจัดการเรื่อง Retry
- การทำ Fault injection
- มีระบบ monitoring และ dashboard สำหรับ sevice ต่างๆ
- การจัดการเรื่อง traffic splitting ของ service เช่น 60% ของ traffic ให้ไปทำงานที่ service version 1 และอีก 40% ของ traffic ให้ไปทำงานที่ service version 2
- Canary deployment / Blue Green
เราเลือกใช้เพราะ Linkerd เพราะ Lightweight, High performance, Security และตัว Config ของ Linkerd ง่ายๆไม่ซับซ้อน Feature ที่เราใช้ตอนนี้ก็ mTLS, traffic splitting, canary deployment
GitHub Actions
Benefit
- Fast Integration Github ecosystem.
- Very easy to use.
Tradeoff
- Feature น้อยกว่าเจ้าอื่นๆ เช่น Jenkins, CircleCI, Travis CI

เราเลือกใช้ Github Action ทำ CI/CD เป็นหลัก เพราะด้วยความง่ายของมัน ใช้คู่กับ ArgoCD ยิ่ง Powerful เข้าไปอีก การจัดการ Deploy ที่ต่าง Cluster กัน และด้วยความสามารถของ ArgoCD ที่จะช่วยทำให้ทุกๆ การ Deploy ของเรานั้นมีความ Smooth มากขึ้นด้วย
GraphQL
เราใช้ GraphQL เป็น API Gateway ที่รับ REST APIs เพื่อช่วย Aggregate รวบรวมข้อมูลจาก Service ต่างๆ ของเราให้ ฝั่ง Client ใช้ได้ง่ายขึ้นและสะดวกมากขึ้น
gRPC
Benefit
- เร็วกว่า REST APIs (HTTP/1.1) ตัว gRPC วิ่งบน HTTP/2
- การรับส่งข้อมูลเป็น Binary ซึ่งทำให้ขนาดเล็กและเร็วมากๆ
- รองรับทั้งการเขียนแบบ Synchronous และ Asynchronous
- รองรับการทำงานแบบ Streaming
- ทำงานได้หลาย languages และ platforms
- Auto-generated client code
Tradeoff
- ไม่มี Endpoint เวลาจะ Test ผ่าน Curl เพื่อจะเช็ค Response และตัว gRPC ก็ไม่มีตัว Status Code ด้วย (แต่สามารถไปใช้ตัว BloomRPC ได้, ล่าสุด postman สามารถเช็คได้แล้ว)
- Browser ที่รองรับน้อย (แต่สามารถใช้พวก library gRPC-Web ได้)
- Not human-readable format เพราะเป็น Binary ทำให้อ่านไม่ได้ง่ายเหมือน REST ที่เป็น JSON, TEXT, XML
- Learning curve สูง (REST จะเรียนรู้ได้ง่ายและเร็วกว่า)
- REST มีความยืดหยุ่นที่สูงกว่า
- ตัว code ที่ generated ค่อนข้างจัดการได้ยุ่งยากกว่าการไป Deserialize JSON ตรงๆ
- การทำ Load balancing มีความซับซ้อนกว่า REST APIs แต่เนื่องจากเราใช้ Service Mesh เลยไม่มีความกังวลเรื่องนี้ grpc-load-balancing
เราเลือก gRPC service จากความสามารถในการจัดการกับ Protobuf ที่ต้องเขียนเสมอเป็นการบังคับเราให้มี Schema ของ Service ที่ชัดเจนโดยอัตโนมัติ ประโยชน์อีกอย่างคือเราไม่ต้องยืดติดกับภาษาด้วยอีกด้วย ก็แค่ Implement ตาม Protobuf ตามภาษาที่ต้องการ
AWS API Gateway
เป็น Gateway สำหรับ Access จากภายนอกเข้ามาสู่ Service ของเรา รวมถึงการจัดการ Traffic, CORS support, Authorization, Access control, Monitoring.
OpenVPN
เราใช้สำหรับการ Access เข้า Network ต่างๆ ของ Service เรา ช่วยในเรื่องการจัดการ Security, Permission การ Access Service ต่างๆ ของ Team ให้ปลอดภัยมากขึ้น
Infrastructure as Code(IaC)

Pulumi
Benefit
- ใช้ Typescript ไม่ใช่ YAML เหมือน Terraform
- เขียน Test ได้ง่ายไม่ว่าจะเป็น Unit testing หรือ Integration testing
- ถ้าใช้จนคล่องมือจะรู้สึกว่าจัดการของต่างๆ ได้ง่ายผ่านการเขียนโค้ดและ Pulumi command ต่างๆ ออกแบบมาอย่าง Ergonomic (เช่นเดียวกันกับ Terraform, ตัว Pulumi มีการจัดการ Stack และ Preview ตัว State ที่จะ Deploy ได้ไม่ยาก)
Tradeoff
- จัดการ state ค่อนข้างยาก
- เบื้องหลังยังทำเป็น Terraform อยู่
- Community น้อยกว่า Terraform

เราเลือก Pulumi แทนที่จะเป็นเจ้าดังอย่าง Terraform เพราะ Pulumi เป็นการเขียน Code จริงๆ ไม่ใช่ Declarative ด้วย HCL (HashiCorp Config Language) ทำให้เวลา Pulumi test ง่ายกว่า ทำ Logic บางอย่างที่ทำได้ใน Code เช่นการ Loop, Condition ต่างๆ ได้ง่ายกว่า
Pulumi เคยช่วยชีวิตเราเอาไว้แล้วครั้งนึง เมื่อคนในทีมไปเผลอลบ Network ตัวนึงทิ้ง ทำให้ระบบทั้งหมดไม่สามารถ Access ได้จาก public internet เราเลย Run คำสั่งให้ Pulumi ช่วย Check State ของ Infra ให้หน่อย และซ่อมในส่วนที่เปลี่ยนไป ที่ไม่ตรงกับตัว Code Pulumi เรา เราจึงกู้ Infra ทั้งระบบขึ้นมาได้ในเวลาไม่ถึง 10นาที
Helm
เราเลือกใช้ Helm เป็น Template ในการจัดการการ Deploy resource ต่างๆ ขึ้นบน Kubernetes เนื่องด้วยเรามี Service จำนวนมากทำให้ Helm มาช่วยจัดการในเรื่องของการช่วยลด Code Duplicate ของ Kubernetes manifest file ได้มาก
Data Pipeline 🏗

Argo Workflow
Benefit
- Setup เข้ากับ Kubernetes cluster ได้ง่ายมาก
- ทำงานร่วมกับ Argo ได้ดี เช่นเราสามารถ manage ตัว workflow ต่างๆ ได้ด้วย repository ที่ให้ ArgoCD ไปจัดการต่อ
- ใช้แค่ YAML ไม่ยึดติดกับภาษาใด ภาษานึง
- ใช้ร่วมกับ Docker ได้ง่าย
Tradeoff
- จัดการ workflow ที่ซับซ้อนได้ยาก เมื่อเทียบกับ Airflow
เราเลือกใช้ Argo Workflow ทีมมี Explore ตัวฮิตอย่าง Apache Airflow แล้วรู้สึกว่า การ Setup มันค่อนข้างใช้เวลาและทุกอย่างมัน Support บน Python มากกว่า คือถ้าอยากจะ Seemless ต้องเขียนบน Python ด้วยความที่เรายังอยากใช้ Rust อยู่ และ use case ของเราไม่จำเป็นต้องใช้ SDK ของ Airflow บน Python ขนาดนั้น เราเลยเลือกใช้ Argo Workflow แทน โดยสามารถ Setup เสร็จได้ภายในวันเดียวเท่านั้นเอง
GitOps

ArgoCD
Benefit
- Store all Kubernetes resource configuration in Git.
- Once Git is modified, apply changes to the cluster immediately and fully automated.
- Feature เยอะกว่า Flux
Tradeoff

เราเลือกใช้ ArgoCD มาช่วยในการเก็บข้อมูลทุก Service บน Kubenetes ทุกครั้งที่มี Change ที่เกี่ยวกับ Deployment บน Github ตัว ArgoCD สามารถ Deploy Change ไปยัง Kubenetes ได้ทันที (แต่อยู่ที่เราตั้ง syncPolicy ของ ArgoCD Config ด้วยว่าจะ automate ไหม) นอกจากจะช่วยเก็บข้อมูลแล้ว ยังช่วยให้การ Deploy Code ไปยัง Kubernetes ปลอดภัยขึ้นและมีความ Smooth มากขึ้นด้วย
หลักการทำงานเบื้องต้นของ ArgoCD โดยจะ Deploy Canary Pod ไปลองก่อนจนมั่นใจว่า Code ตัวใหม่ไม่มีปัญหาอะไร จึงจะ Rollout Pod ทั้งหมดให้เป็น Code ใหม่
Application Development 💻
Domain-Specific Context
- Cloud Infrastructure.
- High reliability, availability, and scalability.
AWS MSK
Data Pipeline Service ของทาง AWS ข้างในเป็น Kafka
AWS Secret Manager
เราเลือกใช้เพราะเอาไว้เก็บพวก Secret ต่างๆ ของ Service เราทั้งหมด เช่น Database Password หรือ API Secret, etc.
AWS Route53
DNS service ของทาง AWS
AWS Lambda
Function as a service ในที่นี้เราเอามาใช้ทำ Whitelist IP และใช้สำหรับกับการจัดการ Event-driven จาก AWS services ต่างๆ ได้สะดวกและง่ายขึ้นด้วย
AWS Simple Queue Service
เราใช้ส่ง message event ของแต่ละ AWS service ในที่นี้เราเอาไว้ส่ง s3 create file event ไปที่ Argo workflow
Data Store 🗄
Domain-Specific Context
- Cloud Infrastructure.
- High reliability, availability, and scalability.
AWS ElasticSearch
ใช้สำหรับเก็บ Trace และ Logging data และเก็บข้อมูลกองทุน สำหรับการค้นหากองทุนที่ต้องการโดยมีเงื่อนไขที่ซับซ้อน
AWS ElastiCache
เราเลือกใช้ In-memory database เพื่อใช้ในการลดโหลด Query, Request ต่างๆของ service เรา
AWS Aurora
Database ที่ใช้เก็บข้อมูล โดยที่เป็น PostgreSQL แยกเป็น writer node กับ reader node
AWS ECR
ใช้สำหรับเก็บเวอร์ชันของ Docker image ส่วนพวก Feature ที่เราใช้ก็ Image Scan, Lifecycle Policy
AWS S3
ใช้สำหรับเก็บไฟล์ต่างๆของ Service เรา
Logging & Monitoring 🖥

Domain-Specific Context
- Universal Instrumentation across Tech Stack. Not like one library for metrics, another for logs, etc.
- Vendor Neutral. Avoid Vendor Lock-in.
OpenTelemetry & Collector
Benefit
- Universal Instrumentation across Tech Stack.
- Vendor Neutral.
Tradeoff
- Relatively new. Some features are not even supported yet.
เราเลือกใช้ OpenTelemetry เพราะช่วยในการจัดการเรื่อง tracing กับ metrics และทำให้ application ไม่เกิด vendor lock-in กับระบบ tracing หรือ metrics ที่ใดที่นึง อีกหนึ่งเหตุผลคือมันเขียน pipeline ได้ง่ายมากๆ ด้วย
เพิ่มเติม: สำหรับ Metrics ใน kubernetes เราใช้ kube-prometheus-stack เป็นตัวรวม Metrics ข้างในมี Metrics ย่อยๆ ที่เราใช้ก็ kube-state-metrics, cadvisor, node-exporter เป็นหลัก และขน Metrics ต่างๆ โดยใช้ OpenTelemetry Collector ส่งเข้าไปใน AWS AMP ซึ่งใช้งานสะดวกมากๆ
Fluentd
เป็น parser และ filter พวก log message ตาม format ที่เราต้องการก่อนที่จะเก็บลง database หรือยิงไปที่อื่นๆ
Fluentbit
เราเลือกใช้ Fluentbit เพราะ lightweight และเรื่องความเร็ว ตัว Fluentbit เป็น Agent ในการกวาด Logs ของ service ต่างๆ ของเรา ที่อยู่ใน Cluster
AWS AMP
เราใช้ Prometheus สำหรับการจัดเก็บข้อมูล Metric ต่างๆ ของระบบ โดยเลือกใช้ AWS Managed Service for Prometheus ในการจัดการ Prometheus server ด้วยความที่เป็น manage service ทำให้ทีมไม่ต้องเสียเวลาในการ Setup, Maintain รวมถึง feature อื่นๆ ที่จำเป็นเช่น Security, Scaling, Availability
Grafana
เราใช้ Grafana ในการทำ Observability ต่าง ๆ และมี dashboard ดูสถานะ service ของเราต่างๆ
Kibana
เป็น Dashboard ใช้สำหรับ Query ElasticSearch
Jaeger
Benefit
- ช่วยให้ทีมเห็นปัญหาด้าน Performance, Latency ระหว่าง service ต่างๆ ได้ตรงจุดและง่ายขึ้น
- Open Source.
- CNCF Project.
Tradeoff
- ต้องมีติดตั้ง Component เพิ่มอีกหลายๆ ตัวเช่น collector, jaeger UI, jaeger ingest
ปัจจุบันทุกๆ Service ของเรา ข้อมูล Tracing ถูกเก็บเข้า Jaeger ทั้งหมดแล้ว ตัว Jaeger เองใช้งานได้ดี
Testing 🧪

Codecov
Benefit
- Beautiful Reports, Interactive Commit Graphs.
- Easy setup.
- GitHub integration.
เราใช้ทำ Code coverage โปรเจคของเราทุกอันมี Test coverage หมด แล้วต้องไม่ต่ำกว่า 85% ไม่งั้น CI จะ Fail
K6
Benefit
- Test scripts are written in javascript.
- Custom metrics.
- มี Virtual Users ที่จำลอง Connection ที่ทำให้การ Test สมจริงขึ้น
- มีตัวช่วยแปลงจาก postman collection เป็น Script เลย
- Export report results เข้า Grafana, CSV, CloudWatch, etc ได้
- Easy to use.
เราเลือกใช้ k6 เอาไว้ทำ Load test สามารถเขียนเป็น Script ได้ ในตัว k6 มี Feature test ต่างๆให้ใช้ง่ายมากๆ ไม่ว่าจะเป็น Smoke testing, Soak testing, Stress testing อีกอย่างพวก Report Results ก็ดูง่ายมากๆ
เพิ่มเติม: เรายังใช้รวมกับตัว easygraphql-load-tester เพื่อช่วยในการจัดการ Generate Queries ของ Schema ใน GraphQL ของเราในการทำ Load test เพื่อให้มียืดหยุ่นมากขึ้น
On-Chain ⛓

ในส่วนนี้ยังอยู่ในระหว่าง Explore & POC และตอนนี้ทีมเราได้ทำ Open-source on-chain side project ไว้สำหรับการจ่ายเงินเดือนแบบ real-time ผ่าน blockchain บน Solana โดยใช้ภาษา Rust สามารถเข้าไปดู source code ได้ใน git repository ด้านล่างเลยครับ
Other 🛠
Mingrammer
Benefit
- diagram as a code.
- Easy to write.
- No need to spend time arranging the diagrams (and no need to write the style).
- Easy to see the changes when looking at the Diff between all versions.
Tradeoff
- Does not allow for a wide variety of shapes, detailed colors, line changes, or visually optimizing complex layouts.
ใช้สำหรับสร้าง diagram ต่างๆ ของระบบเรา สามารถดูตัวอย่างได้จากภาพ Section Infrastructure ข้างบน
Husky
Benefit
- Set standard team.
- Automate checking (styles, tests, linter).
Tradeoff
- Slow development of the life cycle.
ใช้สำหรับจัดการ Git hooks การกำหนด Rule, Quality ต่างๆ ให้ทีมทำงานเป็นมาตราฐานเดียวกัน เช่น conventional commits, styles guide, tests, linter, audit, etc.
Future 🚀

Architecture x86 to ARM — ปัจจุบันเรามีหลายๆ อย่างของเราย้ายไป ARM บ้างแล้ว และเราได้ลองเอา Code Rust ไป Build เป็น ARM ดูแต่ใช้เวลา Build เป็นชั่วโมงเลย!! เรายังคงต้อง Explore วิธีใหม่ๆ อีกต่อไป!!
Chaos Engineering — เราจะลองใช้ chaos-mesh เพื่อเป็นการทดลองให้ระบบของเรามีความยืดหยุ่นมากเพียงพอต่อสถานการณ์รุนแรงต่างๆ ที่ส่งผลต่อการทำงานได้ ให้ระบบของเรามี Resilience มากขึ้น
WASM — เรามีแผนจะลองใช้ WASM กับ Rust ละดูว่าจะเร็วกว่า Native ของ Rust ไหม หรืออาจจะ Deploy แทน Kubernetes krustlet แต่เหมือนจะยังไม่ Support EKS manage node
Conclusion 💡
จะเห็นได้ว่า Tech Stack ของเราจะมาจาก CNCF (Cloud Native Computing Foundation) เยอะหน่อย เพราะ Ava ❤️ Cloud-Native ครับ
Infra ของเราอยู่บน AWS ทั้งหมด จะเห็นว่า Stack ของเราส่วนใหญ่จะใช้เป็น Manage Service ของ AWS เพื่อช่วยในเรื่อง Reliability, Availability, Scalability, Maintainability.
เหตุผลที่เราใช้เพราะเราจะได้ไม่ต้องยุ่งกับเรื่อง Server ต่างๆ มากนัก ได้มีเวลาเอาไป Focus เรื่องอื่นแทน และเรายังชอบในความ Config ได้ทุกอย่างของ AWS เรา Challenge กันเองว่า ไหนๆ ก็ไหนๆ แล้ว เราจะเริ่มแตะ Cloud กันเอง เอาให้มันรู้ลึกๆ ไปเลย
สามารถดู Stack ทั้งหมดของเราได้ที่นี่: https://stackshare.io/avantis/backend
คุณมีปัญหาที่อยากจะเติบโตในสายงาน Dev แต่ไม่อยากไปทำงานสายบริหารใช่หรือไม่?

ยื่น Resume มาหาเราสิครับ 😛
ที่ Ava คุณสามารถเติบโตไปเป็น Tech Specialist เงินเดือนสูงๆ ได้โดยไม่ต้อง Lead Team หรือเป็น Manager เลย ถ้าคุณเจ๋งพอ ยื่น Resume มาเลยครับ เราอยากสร้างทีมไป Global เราอยากทำงานกับคนเจ๋งๆ ทำ Tech เจ๋งๆ เพื่อสร้าง Product เจ๋งๆ ไม่ให้แพ้ทีมไหนในโลก!!
